Improving the fault tolerance of machine learning models
How different machine learning models performed against mislabelled training datasets
Dependable Software Systems students tested how different machine learning models perform against mislabeled datasets. Their results were a surprise – showing that a current assumption among researchers about the best model for training machine learning was incorrect.

Machine learning makes use of a wide range of data from multiple sources. That’s a fine approach if the data is consistent, complete, accurate, valid and complete. But how often is that really the case? When datasets that include erroneous, ambiguous, duplicate and incomplete data are used to train predictive models, the consequences can be significant.
Two students in the Master of Engineering Leadership (MEL) in Dependable Software Systems used their capstone project to evaluate how different machine learning models performed against mislabeled training datasets.
Assessing ensemble learning
Debashis Kayal and Xining Li were particularly interested in exploring the fault tolerance of machine learning algorithms when trained on mislabelled training datasets. They targeted ensemble learning, a machine learning technique that combines several models to create a better predictive model that is more accurate and consistent and that reduces bias and variance errors.
“We had two main questions,” says Debashis. “First, does ensemble learning solve the training data problem? And if so, by how much? We started with a very open-ended problem and then scoped it down to focus on specific machine learning models and data sets.”
They chose to work with two visual recognition data sets (MNIST and CIFAR-10) that are widely used in research for benchmarking models. They then randomly mislabelled 30 per cent of the data to generate a “bad dataset” that they could use to test the resiliency of different machine learning models to data errors.
For their first experiment, they trained five machine learning models – logistic regression, decision tree, Random Forest, AdaBoost and extreme gradient boosting – on both the clean MNIST dataset and the randomly mislabelled MNIST dataset. They measured F1 scores for each as an indicator of precision and recall.
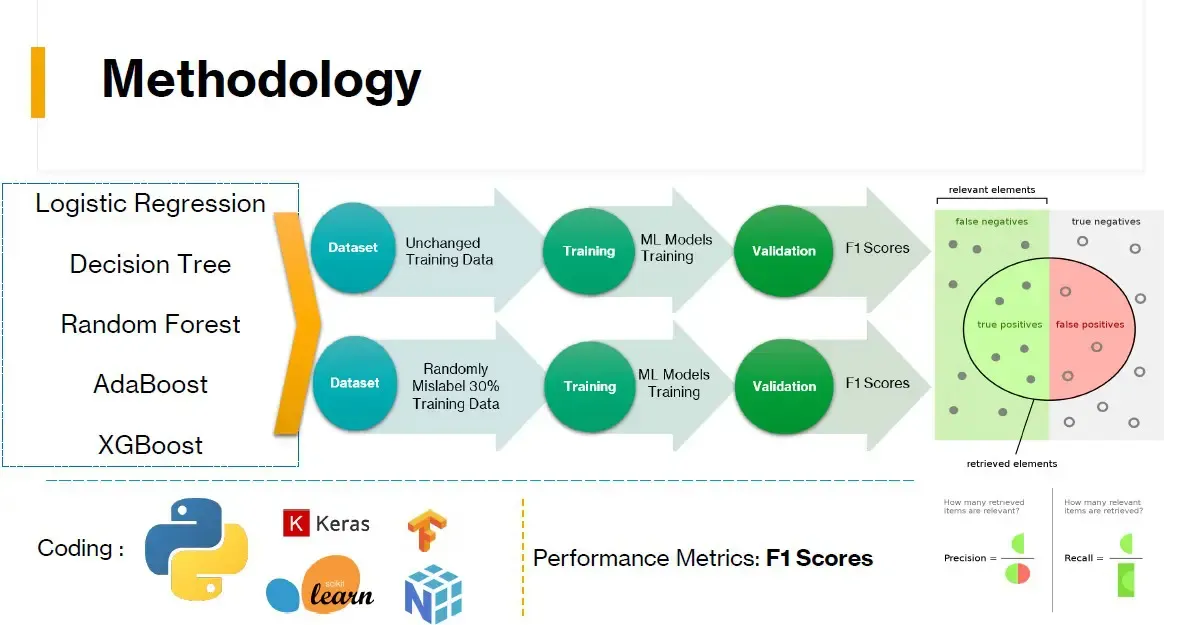
Of the machine learning models, those that incorporated ensemble techniques showed less deterioration, and of those, Random Forest showed the greatest resiliency to poor quality data.
“We were very surprised by the results,” says Debashis. “The research we’d done suggested that extreme gradient boosting would be the best ensemble learning technique. But in the end, our results showed that Random Forest was the best ensemble learning model for mislabelled or bad data.”
Improving performance of convolutional neural network
They then ran a second experiment to see if the best-performing machine learning models from their first experiment could improve the performance of a convolutional neural network approach. They ran this experiment using the more complex CIFAR-10 dataset. The result showed that this was indeed the case.
The two say that their research makes a valuable contribution to the understanding of different approaches.
“It’s currently very expensive and time-consuming to train machine learning software,” says Xining. “If the Random Forest model could be used for pre-training, that would improve performance and reduce training costs.”
“Our conclusion shows that a small experiment conducted by two students in a capstone project can challenge the current dominant assumptions among researchers about the best models for training machine learning,” says Debashis. “There’s lots more research to be done in this area, but it was definitely an eye-opener.”