Machine Learning and Safety-critical Systems

Dependable Software Systems: Machine learning is on the rise
By Philippe Kruchten, Professor of Software Engineering and former Director of the MEL in Dependable Software Systems
Are machine-learning-based systems safe for everyday life? Machine learning is big and getting bigger, with deep learning systems built on neural networks offering solutions to a range of applications. Although this technology can be extremely powerful, it requires having enough properly labelled data to train the learning algorithm. To be clear, we are speaking of data points in the thousands or even tens of thousands, not dozens, for a solid training set. Machine learning brings with it a significant paradigm shift from a traditional approach to solving problems with software, where:
Program + input â computation â result
to the machine learning model, where:
ML Program + Training input â computation â Trained ML program
then
Trained ML program + input â computation â result
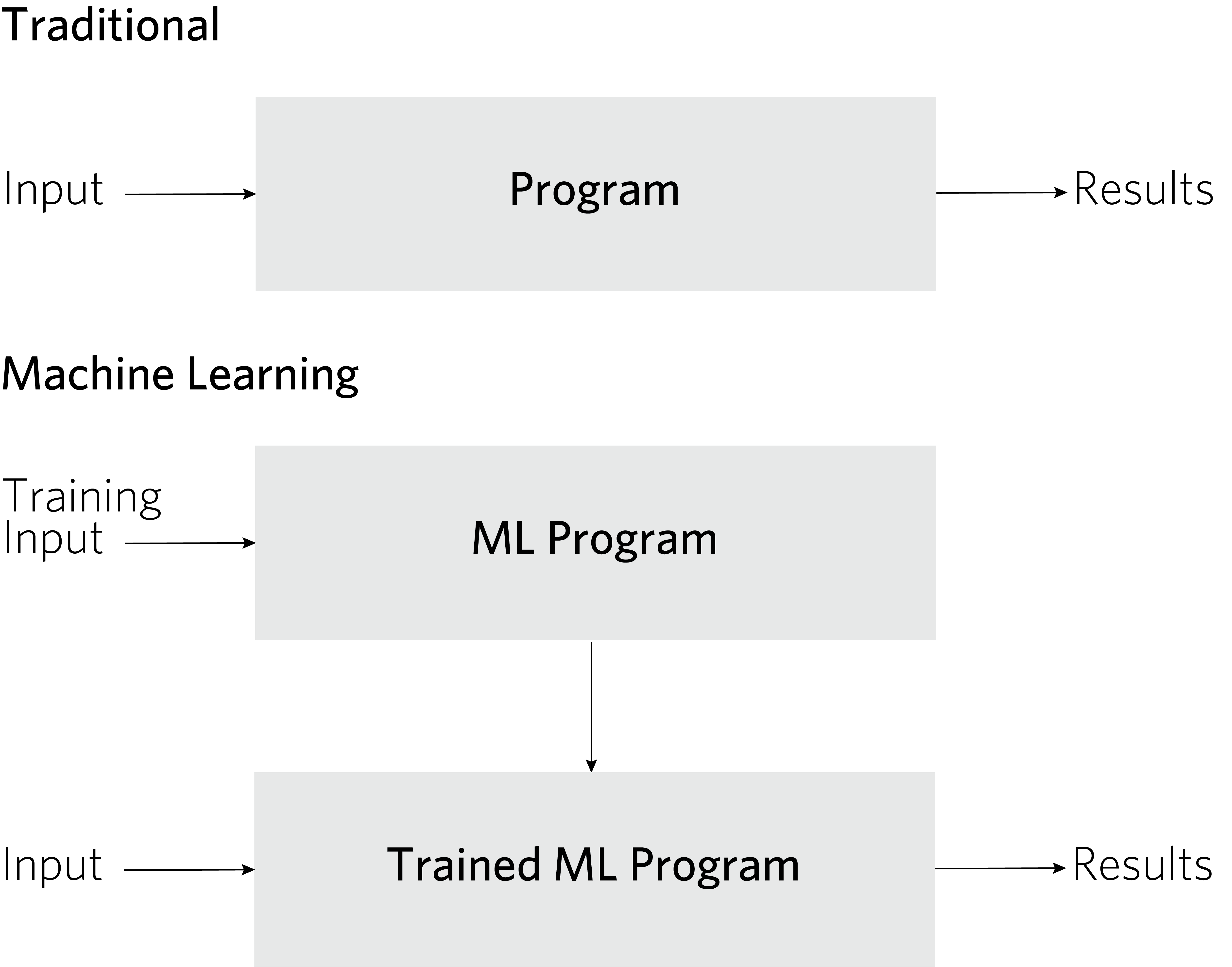
There are two stages in the machine learning paradigm: the learning stage and the operational stage. The training input is data that has been labelled by human beings and it produces a trained machine learning program and with it, raises some important safety issues.
Safety
For some software systems, safety is non-negotiable, and it is imperative that the systems do not harm people (or animals or the environment). This is the case, for example for avionics, nuclear power plants and some biomedical equipment. If they fail, someone may die. The aerospace industry has shown us a vivid example of this recently, with the Boeing Max. Safety is one of the five facets of dependable software systems, along with accuracy, reliability, availability and security.
Until a few years ago, safety in software systems was ensured by keeping humans in the loop to make key decisions or override what computers would do or suggest. Now, however, there is a significant push to remove the human-in-the-loop in various domains.
We see this in the automotive industry, for example, with self-driving cars, but also with robots in industrial applications or medical devices in health care. In some of these cases, it's advocated that humans are not reliable, strong, fast or informed enough to ensure safety performance.
Machine learning and safety
But are machine-learning-based systems safe? To answer this question, let us look at how safety has traditionally been assessed. Historically, engineers build a safety case and they repeatedly inspect the system and software design process, examining what design choices were made and for which reasons. For safety-critical systems, every single line of code must be tested, along with every single possible thread of the program execution. In a machine-learning-based program, things get more complicated. The machine learning code consists of two parts: the code responsible for learning and the code responsible for operations. The code is relatively simple, and mostly domain-agnostic in that it does not include any embedded domain-specific knowledge. As the system learns, it builds a data structure to represent its acquired learning (the actual neurons of the neural network). This training dataset, called a model, is huge, completely opaque and defies inspection by human beings.
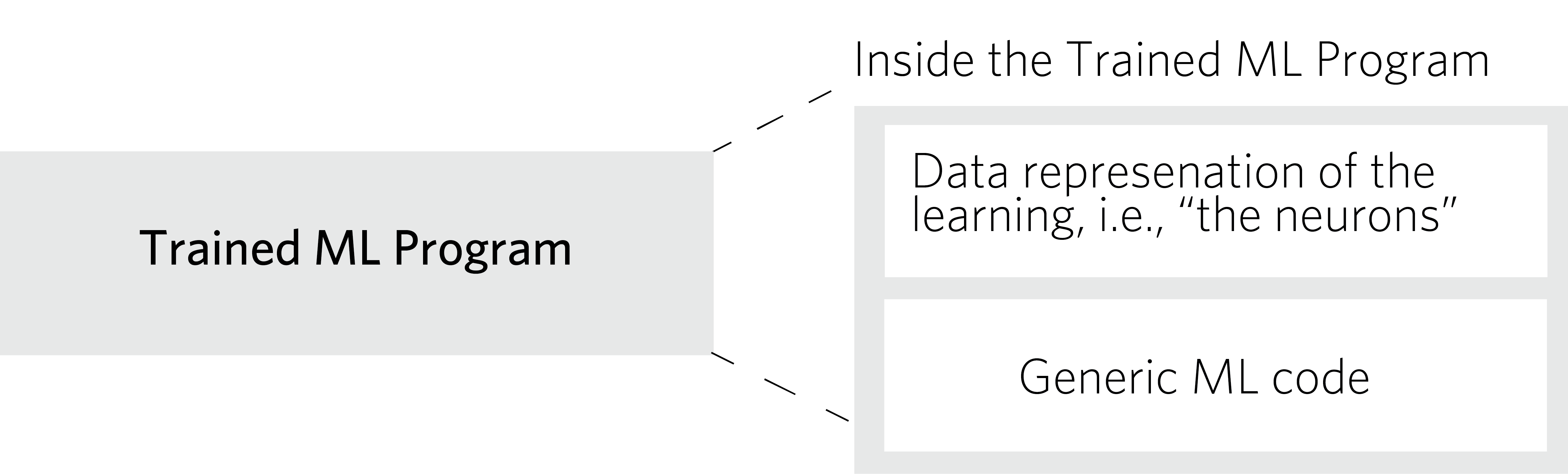
Can this huge model be trusted, if we certify the learner and verify the training data? No, it cannot. We do know that even a properly trained model with a massive amount of properly labelled input dataset may have flaws. In fact, it is relatively easy to produce adversarial examples that cause the system to make a mistake. (See the article Attacking Machine Learning with Adversarial Examples for more on this.)
In short, we do not know yet how to inspect or test the trained program, and inspecting the generic machine learning code (shown in orange above) does not help much, because this code is only a small fraction of the encapsulated knowledge, which is in the data (shown in green in the above diagram).
The problem is even greater if we let the machine learning code continue to learn once the system is put into operation, because the data (neurons) will simply continuously expand or change. This makes building a safety case even more challenging.
Where do we stand in 2020?
This question is still open to research and nobody really knows how to build a safety case for a machine-learning-based system. This means that in some domains, engineers are simply staying away from machine learning, despite its appeal, choosing instead to keep refining the techniques for the traditional model with more systematic testing and traceability of the design decision chain. In the automotive world, for example, ISO standard 26262 (2018) part 6 - Road vehicles - Functional safety, is a key document, complemented by the more recent ISO Standard 21448 (2019) Road vehicles - safety of the intended functionality, where annex G gives some hints (but not many) about assessing off-line training.
Researchers in academia and industry are trying new techniques, such as metamorphic testing. There's a clear need for new ways of developing and assessing strategies to evaluate the safety of machine-learning-based systems.
The Master of Engineering Leadership (MEL) in Dependable Software Systems places questions of machine learning and safety-critical systems at the core of the program. Indeed, for students in the 2019 cohort, the main topic of capstone projects completed in collaboration with industry was on this very topic.
For further reading:
R. Varshney, "Engineering safety in machine learning," 2016 Information Theory and Applications Workshop (ITA), La Jolla, CA, 2016, pp. 1-5. doi: 10.1109/ITA.2016.7888195 Koopman and M. Wagner, "Autonomous Vehicle Safety: An Interdisciplinary Challenge," in IEEE Intelligent Transportation Systems Magazine, vol. 9, no. 1, pp. 90-96, Spring 2017. doi: 10.1109/MITS.2016.2583491 Y. Chen, F. Kuo, H.Liu, P. Poon, D. Towey, T. H. Tse, and Z. Q. Zhou. âMetamorphic Testing: A Review of Challenges and Opportunities,â ACM Comput. Surv. 51, 1, Article 4, January 2018, 27 pages. doi: doi.org/10.1145/3143561

